前言
在日常网络安全运营中,调查服务器主机是否被入侵是绕不开的工作。常见的调查动作就是在主机上执行脚本,批量执行命令将基础数据拉取出来,并做一些简单的规则判断,以便快速确认主机是否已被入侵成功。
在实际工作中,被调查主机通常是生产正在运行的服务器,在调查过程中就会发现存在以下几个问题:
-
安全运营人员具有主机的权限不高,无法获取全面的基础信息,往往需要主机运维人员介入;
-
检测规则不能太复杂否则可能会因为性能问题影响正常业务;
-
固定的检测脚本很难应对不同的调查场景,遇到存疑入侵点而脚本又不能覆盖的,需要反复在主机执行命令;
-
受限于生产环境是最小化部署,意味着平常用的趁手的非内置模块无法加载,限制脚本能力;
-
缺乏统一平台对采集的基础数据进行二次处理、归档、展示,影响调查效率及证据收集;
上述这些问题直接影响安全事件调查和响应的效率,影响平均检测时间(MTTD)、平均响应时间(MTTR)指标,尤其在是在重保期间,需要调查事件太多,留给每个事件调查的时间就不多了。
为了应对在上述不足,应该构建一套应急响应系统框架,这个框架纳入整个安全技术检测体系中,是安全运营建设中一部分,能够与SIEM结合,具备自动化检测、友好展示、方便回溯、快速查看、灵活定制等特点。
为此需要设计一套技术框架,通过更优雅的方式来实现应急响应能力。
考虑到易用性并减少前后端的开发量,借助Splunk是一个很好的选择。Splunk天生就是为了数据分析而生,在字段处理关联分析上具有很大优势,同时还可以解决后端数据存储的问题,是一个很好的解决方案。更多的Splunk介绍,可以参考官网,此处不再赘述。
框架设计
在应急响应系统设计,有几个关键步骤:
-
数据采集:需要脚本在被调查主机上执行脚本,获取系统状态快照;
-
脚本执行:脚本能够推送到目标,完成执行动作,并将执行结果返回到统一服务器;
-
数据解析:后台服务器接收返回的数据,这些数据只是字符串,还需要对字符串解析成结构化数据,才能进行存储和分析;
-
数据分析与归档:对获取到数据,以友好的方式展示,并能够进行字段关联,实现分析能力;能够对结果统一归档保存;
每个步骤都应该要有相应的模块做能力支撑,最终实现统一平台。因此可以有如下的框架图:
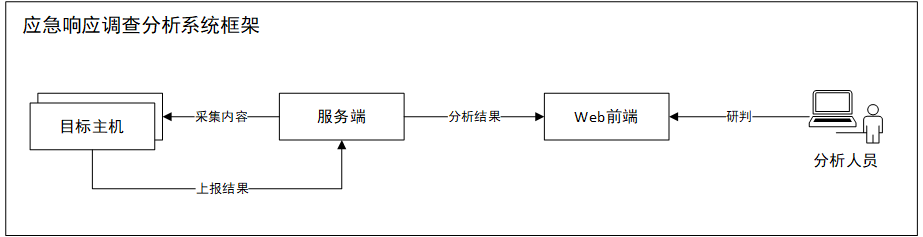
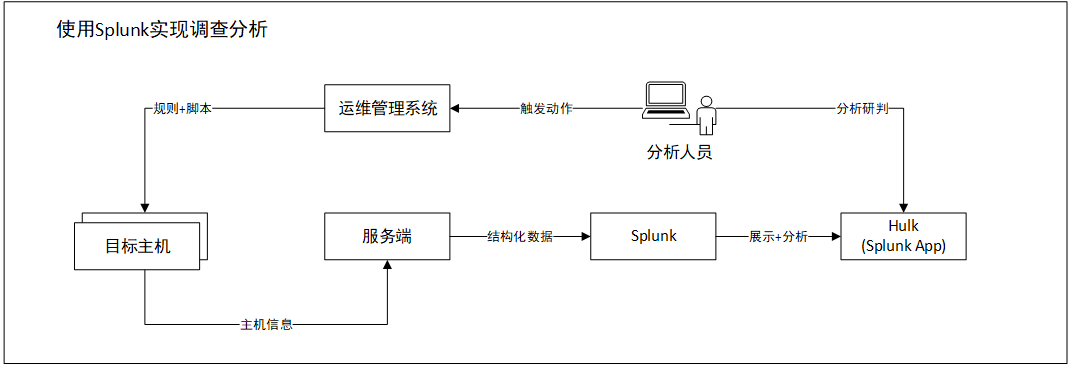
本文中,使用Splunk+运维平台实现一个可持续运行的调查分析框架,如下图:
脚本设计
在被调查主机上执行脚本是整个调查分析关键的第一步,所以在脚本需求上,需要仔细斟酌。
考虑到应急响应场景,更多的是在确认主机是否沦陷,这是一个人工排查过程,需要主机上操作系统和应用服务的基础数据供分析人员判断和决策,好比“专家模式”肯定会比“简单模式”显示更多的信息,所以脚本采集的最终数据应该以基础数据为主。
其次,考虑到应急响应千差万别,可以不同的响应处理类型需要不同类型的数据,这就要求脚本是能够灵活定义的,能够适应不同的情况,也可以尽可能降低脚本开发和维护难度;
最后,被调查的主机通常的是生产的主机,是在生产环境中执行命令,要保证采集内容是可靠的、安全的。这就要求在采集执行动作是系统能够执行的,例如采集命令是标准模块,保证最小化部署的主机也具备相应的执行能力,其次,执行命令多多少少都会对系统产生一定影响,就要求所有执行都应该简单高效,降低对主机性能的影响。
综上,脚本设计应该考虑:
- 能够采集原始基础数据,最少应该包括进程、网络、文件、账号等基础信息;
- 脚本代码和采集规则分离,以规则文件形式定义采集内容,并对常见的采集方式规则化处理;
- 主机执行的脚本仅做数据采集,不在逻辑检测。
代码与规则分离
目前所看到大部分的应急响应工具都是强耦合,一条命令对应一条检测规则,检测多条规则需要执行多条命令,脚本代码不能重用,随着累计应急响应不同场景的增加,只能不断累加代码,最终导致代码臃肿,后期维护难度巨大;
采用代码与规则分离后,采集内容和采集执行命令分开,将每个采集的具体动作“原子化”,这样就可以在约定规则内重用代码,应对不同响应场景,只需要调整采集规则即可。更为重要的是,规则化的脚本,还可以针对不同的SOP场景执行不同的采集数据要求,可以更好的贴近自动化处置理念,相比之前的一坨坨代码和检测逻辑混合的脚本,以规则方式定义能够更直观查看数据采集方式、采集方式;
要做到代码和规则,需要做以下几步:
-
定义采集方式:使用什么方式获取数据,以及执行的具体内容
-
定义输出方式:在前者采集完成后,是否需要下一步的再处理,例如获取到的文件列表,是否要继续获取文件内容;
-
定义解析方式:解析方式与采集方式或格式输出有关,具体的解析方式需要在后端单独实现
例如,可以设计这样一个采集规则:
- id: C0031
name: 获取执行文件状态/usr/bin
description: 获取执行文件状态/usr/bin
category: sysenv
source:
action:
method: stdout
from: "find /usr/bin/* | xargs stat"
parser:
method: command_stat
这条规则是yaml格式,关键的内容在source和parser两个字段内,source定义了采集数据的方式,action表示这条规则采集的动作,比如例子中的stdout表示的是执行命令,具体是什么命令是由后面的from字段来定义的,例子中的find /usr/bin/* | xargs stat表示执行shell命令获取/usr/bin/*目录下所有文件的状态。parser定义的是对采集的数据解析的处理方法,这个方法是在服务端定义并执行的,不同数据采集方式需要不同的解析方法来对应,解析方法目的就是把字符串内容解析成结构化的数据,以便能够完成检索、存储功能。
为了便于后续的维护和分析处理,还设计了name、description、category几个字段,可以一目了然规则作用。
以上例子只是列出其中一部分“原子化”的操作,例如还有遍历目录、读取文件、条件过滤等操作,也是可以一块被定义的。
在实际运行中,脚本会先加载数据采集的规则文件,解析规则文件内容,最终按照规则来采集数据。当把常见的采集动作都“原子化”后,基础的脚本就不需要变更了,后续维护只需要维护对应的规则即可。
执行平台
脚本方案有了,接着要解决的是执行的问题。
对于主机数量非常大的组织,应该统一运维管理平台,再不济也应该有批量运维工具,安全运营人员应该借助组织内已有的运维基础能力,去执行检测方案。如果组织内没有,那可以考虑使用ssh远程执行的方式实现。
执行方式:
- 组织内自研的统一运维平台,这个平台可以统一推送并执行脚本;
- 开源的自动化运维工具,例如 ansible、saltstack、puppet;
- 使用ssh远程命令执行;
上述3种执行方式视实际生产环境而定,最佳实践方式是依托组织内运维部门所提供的工具或平台来执行,最大降低安全部门的运维管理成本。
数据解析
被调查主机按照预定的规则执行完脚本后,需要上传数据,由于在采集步骤不对数据处理,就需要在后端根据parser所指定的方法解析成结构化数据。
举个例子:
在主机上执行脚本会包含ps -ef命令,这个命令可以输出当前系统状态,就像下面这样子的:
root@DESKTOP-R11URQV:~# ps -efwww
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 08:02 ? 00:00:03 /init
root 9 8 0 08:02 pts/0 00:00:00 -bash
root 549 1 0 08:06 ? 00:00:00 /init
root 550 549 0 08:06 ? 00:00:00 /init
root 551 550 0 08:06 pts/2 00:00:00 -bash
root 597 551 0 08:06 pts/2 00:00:01 python3 main.py
root 600 599 0 08:06 pts/3 00:00:00 -bash
root 708 599 1 08:07 ? 00:03:16 splunkd -p 8089 start
root 709 708 0 08:07 ? 00:00:11 [splunkd pid=708] splunkd -p 8089 start [process-runner]
root 775 709 0 08:07 ? 00:01:27 mongod --dbpath=/opt/splunk/var/lib/splunk/kvstore/mongo --storageEngine=mmapv1 --port=8191 --timeStampFormat=iso8601-utc --smallfiles --oplogSize=200 --keyFile=/opt/splunk/var/lib/splunk/kvstore/mongo/splunk.key --setParameter=enableLocalhostAuthBypass=0 --setParameter=oplogFetcherSteadyStateMaxFetcherRestarts=0 --replSet=6BA58D29-BEB7-4A37-BAD5-EC1D1682274B --bind_ip=0.0.0.0 --sslMode=requireSSL --sslAllowInvalidHostnames --nounixsocket --noscripting
root 864 709 0 08:07 ? 00:00:12 /opt/splunk/bin/python3.7 -O /opt/splunk/lib/python3.7/site-packages/splunk/appserver/mrsparkle/root.py --proxied=127.0.0.1,8065,8000
root 888 709 0 08:07 ? 00:00:39 /opt/splunk/bin/splunkd instrument-resource-usage -p 8089 --with-kvstore
root 14490 709 0 11:37 ? 00:00:00 [splunkd pid=708] [search-launcher]
root 14491 709 0 11:37 ? 00:00:00 [splunkd pid=708] [search-launcher]
root 14492 14490 0 11:37 ? 00:00:00 [splunkd pid=708] [search-launcher] [process-runner]
root 14494 14491 0 11:37 ? 00:00:00 [splunkd pid=708] [search-launcher] [process-runner]
root 14597 9 0 11:37 pts/0 00:00:00 ps -efwww
这个命令输出UID、PID、PPID、CMD等信息,这些字符串信息仅限于命令行中看,很难被检索或二次利用。例如此时想看mongod这个进程对应网络连接,就需要再执行一次类似netstat -tlunpa | grep mongod这样的命令。如果要查看几个进程,就得进行几次这样的操作,就会导致效率低下。
因此,就需要对输出的信息结构化,转化成可检索可查看的数据,例如:
{'user': 'root', 'pid': '1', 'ppid': '0', 'c': '0', 'stime': '08:02', 'tty': '?', 'time': '00:00:03', 'cmd': '/init'}
{'user': 'root', 'pid': '9', 'ppid': '8', 'c': '0', 'stime': '08:02', 'tty': 'pts/0', 'time': '00:00:00', 'cmd': '-bash'}
{'user': 'root', 'pid': '549', 'ppid': '1', 'c': '0', 'stime': '08:06', 'tty': '?', 'time': '00:00:00', 'cmd': '/init'}
{'user': 'root', 'pid': '550', 'ppid': '549', 'c': '0', 'stime': '08:06', 'tty': '?', 'time': '00:00:00', 'cmd': '/init'}
{'user': 'root', 'pid': '551', 'ppid': '550', 'c': '0', 'stime': '08:06', 'tty': 'pts/2', 'time': '00:00:00', 'cmd': '-bash'}
{'user': 'root', 'pid': '597', 'ppid': '551', 'c': '0', 'stime': '08:06', 'tty': 'pts/2', 'time': '00:00:01', 'cmd': 'python3 main.py'}
{'user': 'root', 'pid': '600', 'ppid': '599', 'c': '0', 'stime': '08:06', 'tty': 'pts/3', 'time': '00:00:00', 'cmd': '-bash'}
{'user': 'root', 'pid': '708', 'ppid': '599', 'c': '1', 'stime': '08:07', 'tty': '?', 'time': '00:03:26', 'cmd': 'splunkd -p 8089 start'}
{'user': 'root', 'pid': '775', 'ppid': '709', 'c': '0', 'stime': '08:07', 'tty': '?', 'time': '00:01:32', 'cmd': 'mongod --dbpath=/opt/splunk/var/lib/splunk/kvstore/mongo --storageEngine=mmapv1 --port=8191 --timeStampFormat=iso8601-utc --smallfiles --oplogSize=200 --keyFile=/opt/splunk/var/lib/splunk/kvstore/mongo/splunk.key --setParameter=enableLocalhostAuthBypass=0 --setParameter=oplogFetcherSteadyStateMaxFetcherRestarts=0 --replSet=6BA58D29-BEB7-4A37-BAD5-EC1D1682274B --bind_ip=0.0.0.0 --sslMode=requireSSL --sslAllowInvalidHostnames --sslPEMKeyFile=/opt/splunk/etc/auth/server.pem --sslPEMKeyPassword=xxxxxxxx --sslDisabledProtocols=noTLS1_0,noTLS1_1 --nounixsocket --noscripting'}
{'user': 'root', 'pid': '864', 'ppid': '709', 'c': '0', 'stime': '08:07', 'tty': '?', 'time': '00:00:12', 'cmd': '/opt/splunk/bin/python3.7 -O /opt/splunk/lib/python3.7/site-packages/splunk/appserver/mrsparkle/root.py --proxied=127.0.0.1,8065,8000'}
{'user': 'root', 'pid': '888', 'ppid': '709', 'c': '0', 'stime': '08:07', 'tty': '?', 'time': '00:00:41', 'cmd': '/opt/splunk/bin/splunkd instrument-resource-usage -p 8089 --with-kvstore'}
{'user': 'root', 'pid': '15314', 'ppid': '9', 'c': '0', 'stime': '11:49', 'tty': 'pts/0', 'time': '00:00:00', 'cmd': 'python3 parser.py'}
{'user': 'root', 'pid': '15315', 'ppid': '15314', 'c': '0', 'stime': '11:49', 'tty': 'pts/0', 'time': '00:00:00', 'cmd': '/bin/sh -c ps -efwww'}
{'user': 'root', 'pid': '15316', 'ppid': '15315', 'c': '0', 'stime': '11:49', 'tty': 'pts/0', 'time': '00:00:00', 'cmd': 'ps -efwww'}
这里解析后的数据是JSON格式的,这些结构化好的数据再传到后台存储,也只有这样的数据才能被检索、被处理。
需要注意的是,对原始数据解析时应该尽可能做到“无损”解析,因为在调查分析中任何细微的信息都有可能是分析的关键因素。
展示与分析
采集的内容解析了,接下来就是要怎么展示这些数据了。
一般来说,要做数据展示都是需要前端界面开发的,如果还需要数据关联或者信息下探,这个界面逻辑会更加复杂;另外,还需要维护一个数据库,做后台存储。这些工作对于没有专业开发能力的安全运营团队来说不是一件简单的事情。
那是否可以有一款应用可以很好的解决这个问题呢?Splunk可能是一个比较好选择。Splunk是一款商业系统,在SIEM领域应用比较广,尤其是在日志处理上有很大优势,唯一缺点就是贵…. 具体的其他信息自行百度,此处过多展开。
当然,Splunk也有免费license,免费的license会限制每日的数据量500M;如果申请开发者license,每日可以有10G;每日的500M数据量在应对响应调查这个事情上,这个量应该够了,一次执行的脚本采集数据量最大就是10来M而已。
选择使用Splunk可以同时解决存储和展示问题,只需要在界面定制需要展示页面和钻取逻辑,就可以把整个功能跑起来了。
Splunk定制配置不难,这里不详细展开,有兴趣的同学可以查看下面的Github项目,有Splunk完整的App源码。下面结合效果动图,阐述下逻辑实现思路。
调查分析
【任务详情】

查看任务详情:
-
任务是每一次执行脚本标识;在真实的响应中,每次脚本执行都是一次对系统状态进行一次快照,这样就有必要通过“任务”这个字段来区分上传的数据都是在同一次环境中的,因为在不同的快照里做数据关联和钻取是没有意义的。
-
事件响应调查是某次具体的行为,在触发本地执行脚本之后,开始响应之前,要先确认下数据采集是否正常,确保被调查的机器采集上来的数据是正常的,且是被正常解析和结构化的。
【调查面板】

详细调查分析:
- 对采集上来的内容,按照“进程”、“文件”、“账号”等类别进行分类,形成几个不同的tag标签页,这样好处是可以尽可能把相关数据关联起来,减少页面切换次数,同时也避免数据过多导致查看内容太长。
【数据钻取】

数据关联是整个功能的核心,也是充分发挥Splunk数据钻取能力体现。
- 直接通过上面过滤的条件,筛选出关注的进程信息;
- 可以点击页面任意一条信息,在不同的结果结果中显示出与该信息关联的信息;例如,通过PID不仅可以直接显示出
ps -ef的打印出的信息,还能够关联对应的lsof文件描述符信息、netstat -tlunpa网络链接信息。
同理,在每个页面上,都可以基于这个思路去完善,只要找到不同数据之间的共同字段,就可以实现在一个页面内全展示,这无疑是可以加快调查分析进度的。
小结
本文旨在借助Splunk的数据收集和分析能力,探索一种可标准化可自动化实现的应急响应机制,以完善在安全运营中更高效完成事件调查闭环。
或许有人会说,“我一个脚本可以解决的事情,何必整那么复杂”。的确是存在这种情况的。但在组织内,体系和标准化是一件更需要考虑的事情。基于平台化的运营建设才是可持续运营的根本,更重要的是基于平台化建设后,才有条件去实现更细粒度自动化响应场景,从根本上解决耗时耗力的问题。
本文还有一部分尚未探讨,就是如何将运营人员的调查分析经验直接展示在“调查面板”上,这个内容就需要进一步借助Splunk的分析,汇总管理风险发现逻辑,在面板上直接将风险内容展示出来。本文权当抛砖引玉,有兴趣的读者可以继续进一步探索。
本文所提到的源码,也一并放在 github: https://github.com/chiww/HotDog.git项目下,有兴趣的小伙伴可以start 或 follow。